
How concurrency and async IO works
什么是concurrency
来自MIT 6.005 Software Construction 的解释:
Concurrency means multiple computations are happening at the same time.
这个解释有点抽象,其实可以分为两个部分:
- “multiple computations”: program需要有多个logic blocks,这些blocks可以互相独立,也可以互相关联。与此相对应的是linear computations,就是program简单的从上到下顺序执行
- “happening at the same time”:听起来简单,其实和很多人想的不一样,这里的same time是conceptally的concept,不是literally的same time。举个例子,如果CPU只有一个core,用time slicing的办法执行多个任务,从application的角度完全可以认为是”at the same time”
总结一下就是满足两个条件:1)多个logic blocks,2)可以同时执行
concurrency的实现1:multi-threading
multi-threading是最经典的一种实现了,几乎从concurrency诞生之初一直被用在需要concurrency的场合。还是借用MIT 6.005的定义:
Making a new thread simulates making a fresh processor inside the virtual computer represented by the process. This new virtual processor runs the same program and shares the same memory as other threads in process.
这里有两个部分:
- new thread is a processor: 可以认为在操作系统层面增加了一个cpu core。通过这种实现,threads就同时满足了concurrency的两个定义:multi-logic-blocks和execute as the same time.
- they share the same memory: 这是一个非常重要的特性(也是很多bug的来源),不同threads之间可以用shared memory/register来communicate,这也是大多数lock的底层实现
可以看到,threading在concurrency的定义之上引入了shared memory,这是因为,绝大多数的multi-threading是需要相互communicate的。(所以不需要cross-threads communicate的program一般不认为是multi-threading programming)这种通信就巧妙地用shared memory来达到了。并且shared memory也产生了另一个重要的概念:lock
lock in multi-threading
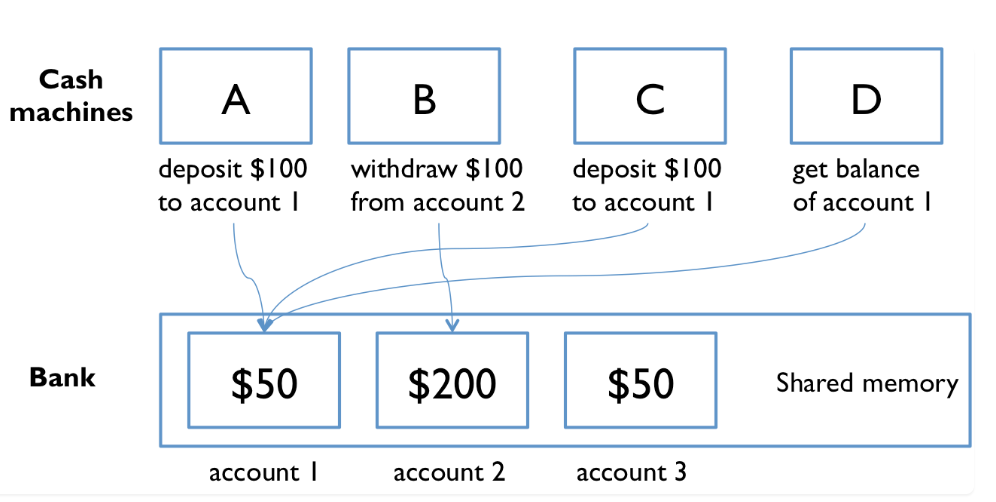
上图是一个典型的lock应用场景,account的信息,比如balance,change history是shared memory。多个cash machine可能同时read/write account。就需要一个lock来保证数据的integrity
#include <iostream>
#include <thread>
#include <mutex>
class BankAccount {
private:
static int balance;
static std::mutex balance_mutex;
public:
// Method to deposit money safely
static void deposit() {
std::lock_guard<std::mutex> lock(balance_mutex);
balance = balance + 1;
}
// Method to withdraw money safely
static void withdraw() {
std::lock_guard<std::mutex> lock(balance_mutex);
balance = balance - 1;
}
// Method to check balance
static int getBalance() {
std::lock_guard<std::mutex> lock(balance_mutex);
return balance;
}
};
// Initialize the static members
int BankAccount::balance = 0;
std::mutex BankAccount::balance_mutex;
int main() {
// Example usage
std::thread t1([](){ for(int i = 0; i < 1000; ++i) BankAccount::deposit(); });
std::thread t2([](){ for(int i = 0; i < 1000; ++i) BankAccount::withdraw(); });
t1.join();
t2.join();
std::cout << "Final Balance: " << BankAccount::getBalance() << std::endl;
return 0;
}
从上面的code可以看到,用传统的multi-threading, std::thread, lock实现的concurrency有明显的特点:
- 需要explicitly create new thread
- 不同threads之间相对独立,当std::thread object创建之后,logic就开始执行。某一个thread.join()被call时,main thread就会等待相应的thread。这些操作都不必须相互依赖
- 不同threads的相互依赖需要logic自己来实现,比如thread A是否需要等待thread B,是需要programer自己实现的。这提高了实现的自由度,但是也会导致implementation的难度提高,引起很多臭名昭著的multi-threading bug
concurrency的实现2:asyncio
async的核心思想是event loop in single thread来解决多个I/O bounded function同时执行的场景。这种设计理念和现在互联网的流行服务架构非常贴合:一个host要处理多个request,每个request中会有多个I/O bounded function。和multi-thread相比,async因为是单线程,设计相对简单,同时代码大大简化。 另外async对于不同task之间的调度也更加精细。multi-thread中,不同thread的执行顺序和时机是由底层代码决定的。而async可以用await等syntax来精细地控制如何在各个task之间分配time slice
await in async
async引入了一个重要的future和await的概念,简单来说,由task自己来claim是否愿意把executor交给其他task,而不是依靠scheduler来preempt。这带来两个好处,第一是可以精细地控制CPU资源的分配,第二是不同task之间的dependency实现起来更加容易:
import asyncio
async def task_a():
print("Task A: Starting")
await asyncio.sleep(2) # Simulate I/O operation
print("Task A: Completed")
return "Result from Task A"
async def task_b(result_a):
print("Task B: Waiting for Task A to complete")
result = await result_a
print(f"Task B: Received '{result}' from Task A")
await asyncio.sleep(1) # Simulate I/O operation
print("Task B: Completed")
return "Result from Task B"
async def task_c(result_a, result_b):
print("Task C: Waiting for Task A and Task B to complete")
result_a = await result_a
result_b = await result_b
print(f"Task C: Received '{result_a}' and '{result_b}'")
await asyncio.sleep(1) # Simulate I/O operation
print("Task C: Completed")
async def main():
async with asyncio.TaskGroup() as tg:
# Schedule Task A
result_a = tg.create_task(task_a())
# Schedule Task B, which depends on Task A
result_b = tg.create_task(task_b(result_a))
# Schedule Task C, which depends on Task A and Task B
tg.create_task(task_c(result_a, result_b))
# Run the main function
asyncio.run(main())
这一段code明显的体现出async的可读性:Task A/B/C之间存在依赖,用await来实现,非常简洁,而且避免了不必要的context switch. 当某个task决定把executor还给scheduler时,就可以用await一个awaitable object,来等待一些费时的I/O操作,当操作完成,scheduler又会把executor交还给task,来继续执行接下来的代码。如果用thread来实现,则不得不用shared object,比如mutex,atomic,比较繁琐
asyncio.Queue
When multiple asynchronous tasks need to read from and write to a shared resource, it’s crucial to manage access to prevent race conditions and ensure data integrity. While traditional locking mechanisms like asyncio.Lock can be used, they may introduce complexity and reduce code readability. Instead, you can employ higher-level abstractions that inherently manage synchronization, leading to more maintainable and understandable code.
当不同的task需要访问同一个resource时,queue是一个非常好用的上层实现。它适用于一个task产生需要处理的数据,另外一个task来处理数据。programmer不需要自己来处理数据consistency的问题
An asyncio.Queue allows tasks to communicate safely by passing data between producers and consumers without explicit locks. This approach is particularly effective when tasks produce and consume items at different rates.
import asyncio
async def producer(queue):
for i in range(5):
await asyncio.sleep(1) # Simulate data production
item = f"item_{i}"
await queue.put(item)
print(f"Produced {item}")
async def consumer(queue):
while True:
item = await queue.get()
if item is None:
# No more items to process
break
print(f"Consumed {item}")
queue.task_done()
async def main():
queue = asyncio.Queue()
# Schedule producer and consumer tasks
producer_task = asyncio.create_task(producer(queue))
consumer_task = asyncio.create_task(consumer(queue))
await producer_task
# Signal the consumer to exit
await queue.put(None)
await consumer_task
asyncio.run(main())
In this example, the producer adds items to the queue, and the consumer retrieves them. The use of asyncio.Queue ensures that access to the shared resource (the queue) is properly synchronized without explicit locks.
asyncio.Condition
An asyncio.Condition combines a lock with the ability to wait for certain conditions to be met, facilitating complex synchronization scenarios. This is beneficial when tasks need to wait for specific states or events before proceeding.
import asyncio
async def waiter(condition, waiter_id):
async with condition:
print(f"Waiter {waiter_id} is waiting for the condition")
await condition.wait()
print(f"Waiter {waiter_id} has been notified")
async def notifier(condition):
await asyncio.sleep(3) # Simulate some processing
async with condition:
print("Notifier is notifying all waiters")
condition.notify_all()
async def main():
condition = asyncio.Condition()
waiters = [asyncio.create_task(waiter(condition, i)) for i in range(3)]
notifier_task = asyncio.create_task(notifier(condition))
await asyncio.gather(*waiters, notifier_task)
asyncio.run(main())
总结
concurrency是程序变得复杂之后的必然要求:硬件上需要utilize所有的core来优化程序性能,软件上很多logic都可以描述为logic block的DAG,即相对独立的block可以独立运行,只需要在关键的point互相依赖。这两个需求都可以被concurrency满足。
实现方式上,主要考虑两点:怎么组织多个tasks同时执行,怎么组织多个tasks之间的dependency。
多个tasks同时执行,可以通过multithread或者event_loop来实现。前者适合多个CPU bounded tasks,在多核的环境中;后者适合多个I/O bounded tasks
多个tasks之间的dependency,可以用传统的lock/mutex来实现,也可以用很多上层的抽象,比如await/future, condition, producer/consumer queue.
现代的程序中async/corountine越来越流行,可以满足大部分concurrency的需求。