
LSM Tree Study Notes
blog link: Understanding LSM Trees: What Powers Write-Heavy Databases from yadevblog@twitter
Look inside
There’re several kinds of taxonomy for databases. From data organization perspective, simple data structure could be used as anchor for complex ones. LSM is just a key-value store, similar to any looking-up structures. However combining basic data structure with some other simple but suitable features like cache, sstable to make it very efficient.
Thought: Behind seemingly complex products (LSM is the key data structure of leveldb/HBase/etc), There is often a core concept/component. Understanding it may only take 5% effort of understanding the whole product, which is good enough to learn the philosophy of some famous products.
SStable

Before looking into writing-data process, a concept sstable should be introduced first – it is a file which contains a set of arbitrary, sorted key-value pairs inside. It has several characteristics:
- sorted key-value pair: From high-level overview, sstable is just a sorted key-value pair, the type of key and value could be arbitrary, the size of the sstable is configurable.
- immutable data: Once a certain sstable is flushed into disk, it becomes immutable:Both the index and the store file part. This property is introduced to avoid expensive random access at disk(HDD in particular).
- index could be sparse: Because sstable is sorted, we could only store part of the key-offset pairs
Thought: Some famous algorithms might look surprisingly simple, and super efficient. In other words, complexity is a side effect instead of ‘proof of intelligence’.
Write data
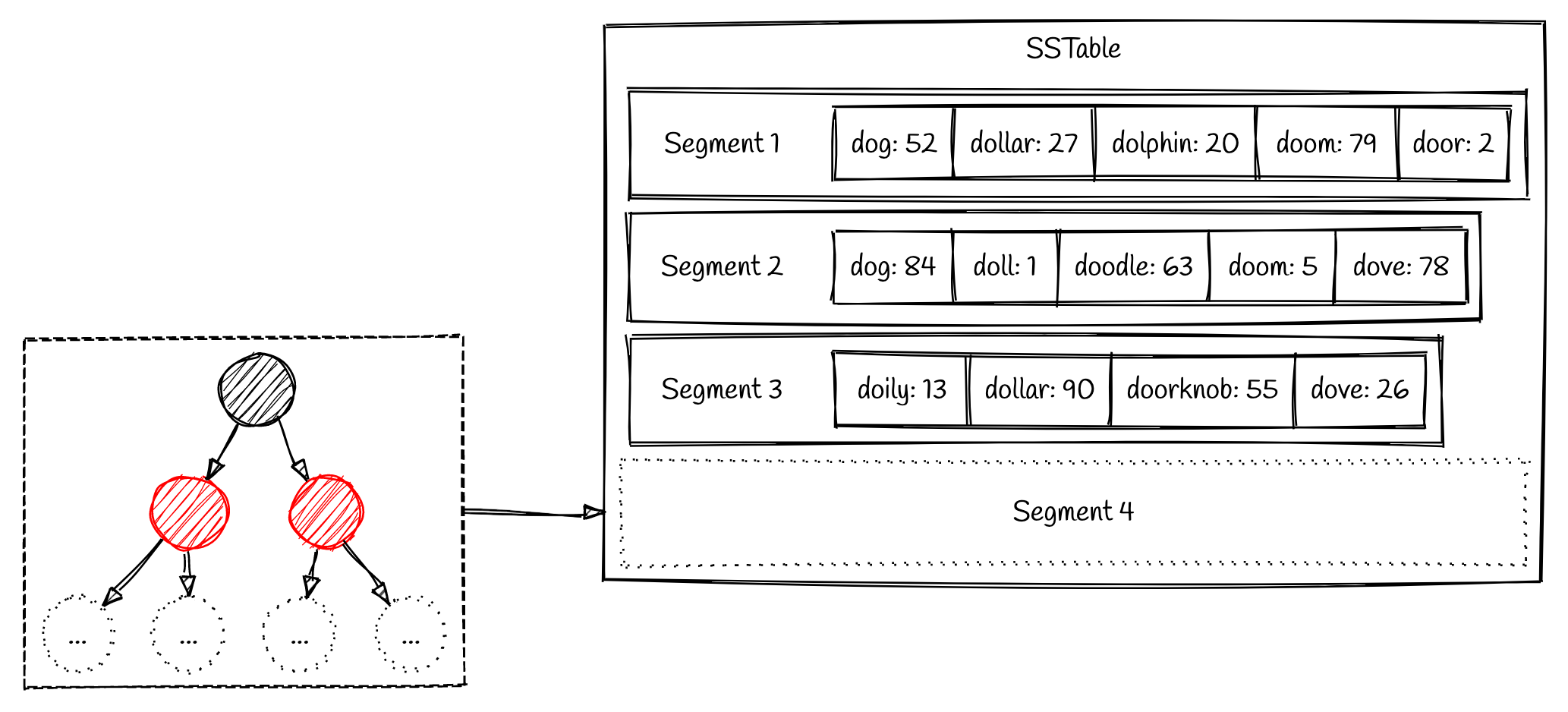 How the data is written? After introducing the sstable concept, the write process becomes clear:
How the data is written? After introducing the sstable concept, the write process becomes clear:
Firstly, we prepare a sstable in memory, called memtable. Like sstable, it also includes two parts: Index and Log. the Index is a Red-Black tree or similar structure, the purpose of Index is to get offset of value in O(n) time complexity. The Log is just a file, each key-value pair is ordered and stored sequentiality.
Secondly, when the memtable is full, it’ll be flushed into disk, adhere to the existing sstable, ordered by flushed time.
Basically there’s how the write path works. There’re also many tricks to make the process more efficient, like sparse index, memetable sizing tuning, etc.
Read data
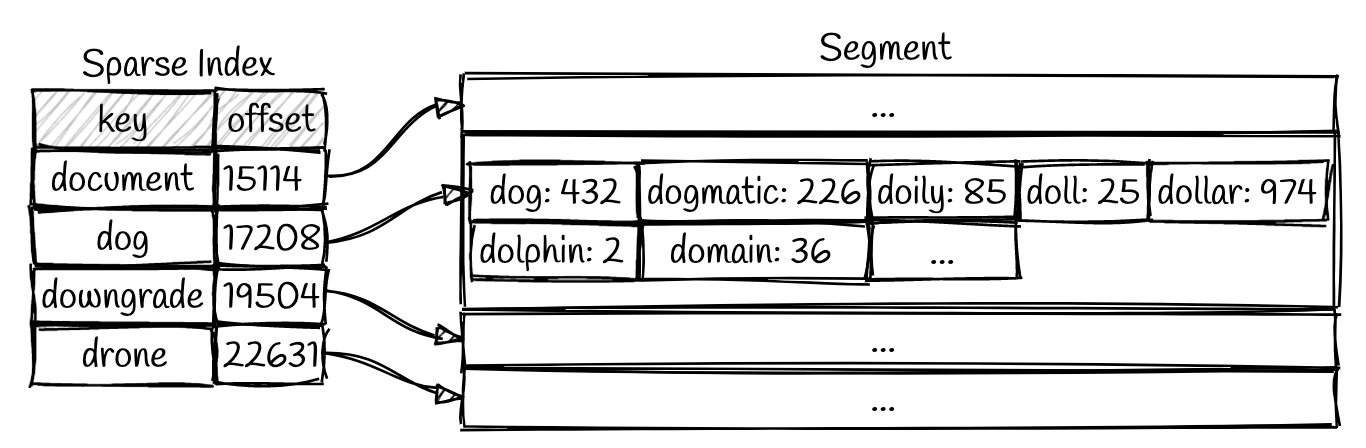
The read operation is designed to adapting properties of disk: convert I/O to as many sequential ones as possible. Following is quoted: “When a read operation is requested the system first checks the in memory buffer (memtable). If the key is not found the various files will be inspected one by one, in reverse chronological order, until the key is found. Each file is held sorted so it is navigable.”
More tricks
Of course the read performance cannot be as good as others like B+ Tree, without some tricks. And usually the tricks is where the intelligence jump-in :p
- Put the page-index into memory. random access in memory is way faster than disk.
- Compaction Periodically merge files to maintain a reasonable num of files.
- Blooming filter An efficient way to check whether a key exists.
- Levelled Compaction Instead of size-based compaction, level-based compaction is used: It guarantee that sstables don’t have overlapping in the same level
In Summary, LSM trees is a typical example that for a challenge problem (build an efficient key-value database, balancing write/read performance), how a complex system evolves, from a simple ideas a viable and useful state, based on multiple iterations and improvement.
Thought: That’s a typical scenario for most of software projects: Understand the problem, propose a simple idea as the right direction, keep polishing to make it perfect.